|
[[440384]] 本文转载自微信公众号「小林coding」,作家小林coding 。转载本文请有关小林coding公众号。 公共好,我是小林。 重庆时时彩棋牌公共背八股文的时候,王人知说念 MySQL 里 InnoDB 存储引擎是选用 B+ 树来组织数据的。 这点没错,然则公共知说念 B+ 树里的节点里存放的是什么呢?查询数据的流程又是如何的? 此次,咱们从数据页的角度看 B+ 树,望望每个节点长啥样。 消息面上,此前公司发布截至2023年6月30日止6个月中期业绩,该集团取得收益人民币15.25亿元(单位下同),同比增加68.2%;公司拥有人应占溢利4.65亿元,同比增加77.99%每股盈利20.5分,拟派发中期股息每股9.06港仙。 开云体育代理
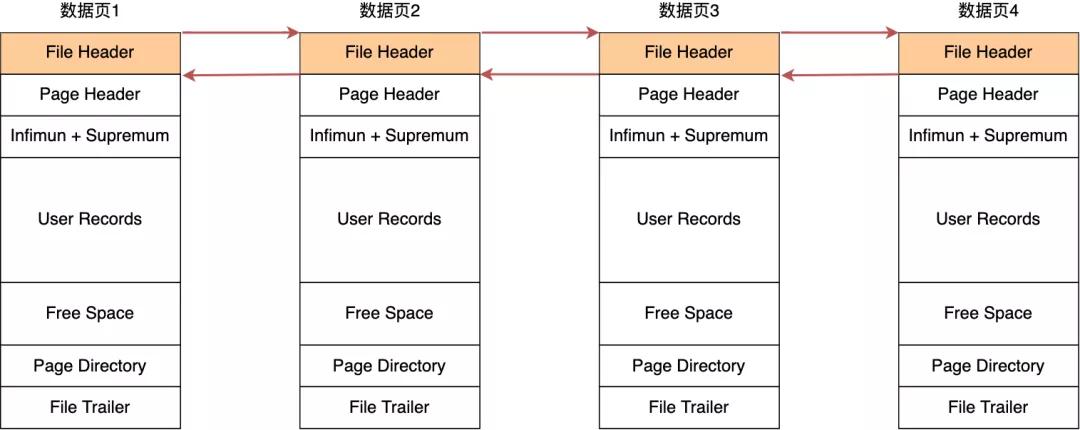
MySQL 撑握多种存储引擎,不同的存储引擎,存储数据的面貌亦然不同的,咱们最常使用的是 InnoDB 存储引擎,是以就跟公共图解下InnoDB 是如何存储数据的。 纪录是按照行来存储的,然则数据库的读取并不以「行」为单元,不然一次读取(也便是一次 I/O 操作)只可处理一溜数据,后果会相等低。 因此,InnoDB 的数据是按「数据页」为单元来读写的,也便是说,当需要读一笔纪录的时候,并不是将这个纪录自身从磁盘读出来,而是以页为单元,将其合座读入内存。 数据库的 I/O 操作的最小单元是页,InnoDB 数据页的默许大小是 16KB,意味着数据库每次读写王人是以 16KB 为单元的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16K 内容刷新到磁盘中。 数据页包括七个部分,结构如下图:
皇冠体育这 7 个部分的作用如下图:
在 File Header 中有两个指针,分别指进取一个数据页和下一个数据页,蚁集起来的页绝顶于一个双向的链表,如下图所示:
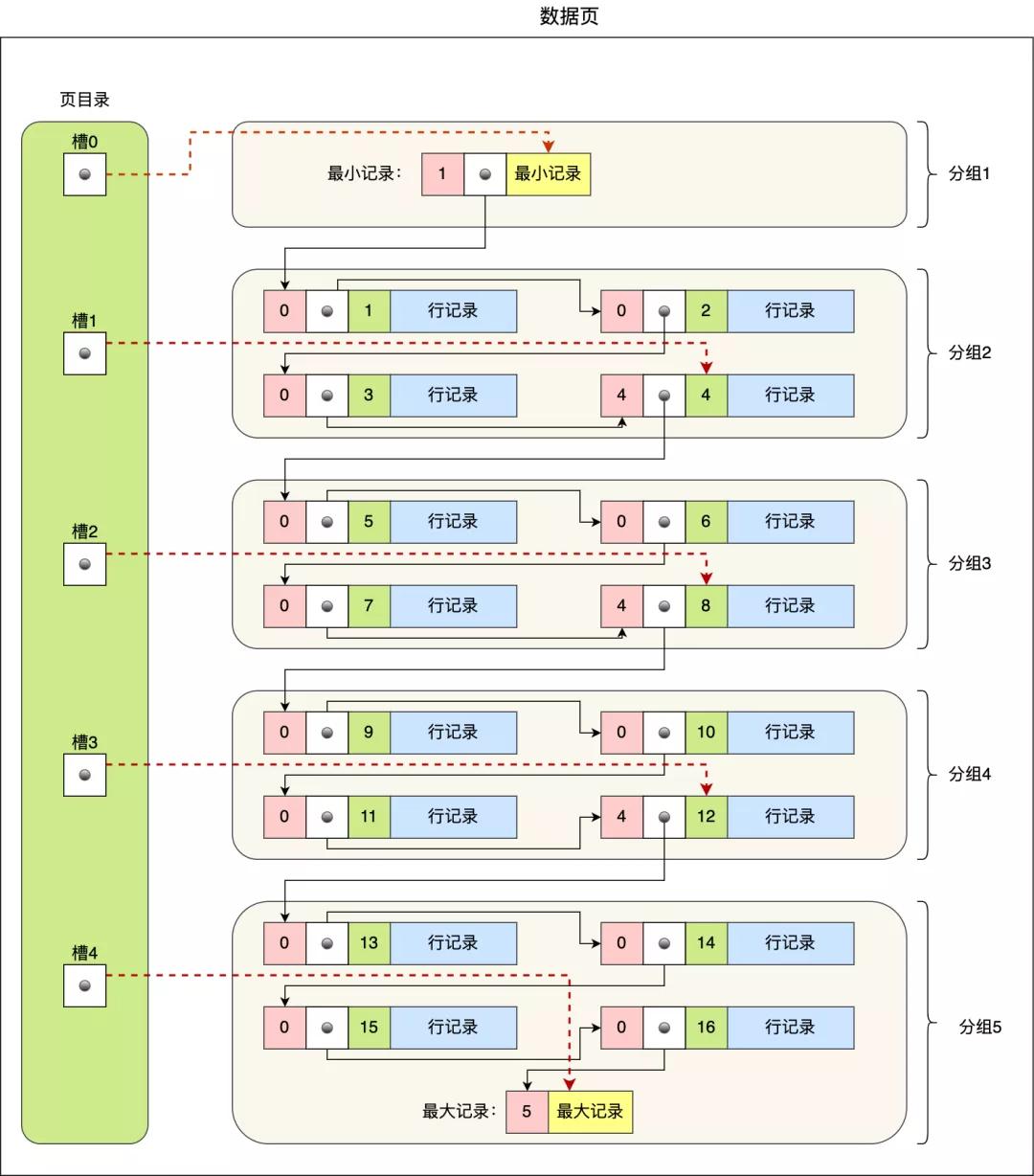
选用链表的结构是让数据页之间不需如若物理上的一语气的,而是逻辑上的一语气。 数据页的主要作用是存储纪录,也便是数据库的数据,是以重心说一下数据页中的 User Records 是若何组织数据的。 皇冠客服飞机:@seo3687数据页中的纪录按照「主键」规章组成单向链表,单向链表的特色便是插入、删除相等浅易,然则检索后果不高,最差的情况下需要遍历链表上的通盘节点才智完成检索。 因此,数据页中有一个页目次,起到纪录的索引作用,就像咱们书那样,针对书中内容的每个章节成立了一个目次,念念看某个章节的时候,不错稽察目次,快速找到对应的章节的页数,而数据页中的页目次便是为了能快速找到纪录。 那 InnoDB 是如何给纪录创建页目次的呢?页目次与纪录的干系如下图:
页目次创建的流程如下: 将通盘的纪录差别红几个组,这些纪录包括最小纪录和最大纪录,但不包括记号为“已删除”的纪录; 每个纪录组的临了一笔纪录便是组内最大的那笔纪录,而且临了一笔纪录的头信息中会存储该组一共有几许笔纪录,行为 n_owned 字段(上图中粉红色字段) 页目次用来存储每组临了一笔纪录的地址偏移量,这些地址偏移量会按照先后规章存储起来,每组的地址偏移量也被称之为槽(slot),每个槽绝顶于指针指向了不同组的临了一个纪录。从图不错看到,页目次便是由多个槽组成的,槽绝顶于分组纪录的索引。然后,因为纪录是按照「主键值」从小到大排序的,是以咱们通过槽查找纪录时,不错使用二分法快速定位要查询的纪录在哪个槽(哪个纪录分组),定位到槽后,再遍历槽内的通盘纪录,找到对应的纪录,无需从最小纪录初始遍历通盘这个词页中的纪录链表。 
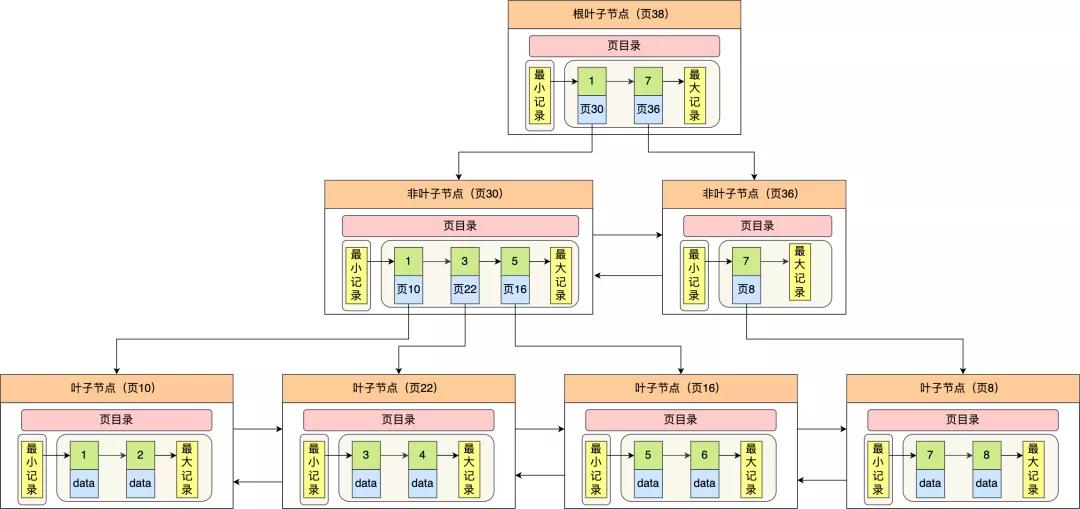
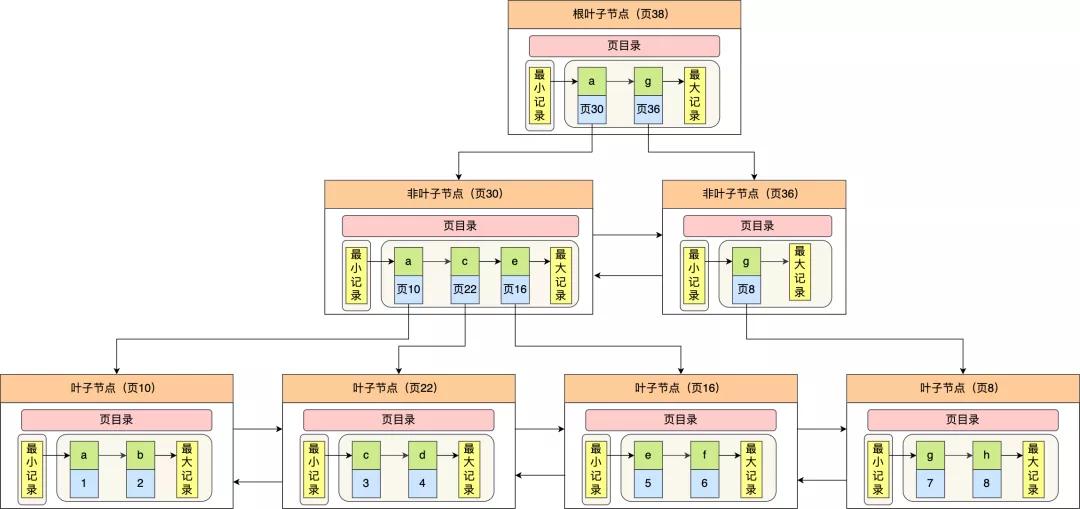
以上头那张图举个例子,5 个槽的编号分别为 0,1,2,3,4,我念念查找主键为 11 的用户纪录: 先二分得出槽中间位是 (0+4)/2=2 ,2号槽里最大的纪录为 8。因为 11 > 8,是以需要从 2 号槽后不时搜索纪录; 再使用二分搜索出 2 号和 4 槽的中间位是 (2+4)/2= 3,3 号槽里最大的纪录为 12。因为 11 < 12,是以主键为 11 的纪录在 3 号槽里; 再从 3 号槽指向的主键值为 9 纪录初始向下搜索 2 次,定位到主键为 11 的纪录,取出该笔纪录的信息即为咱们念念要查找的内容。看到第三步的时候,可能有的同学会疑问,如果某个槽内的纪录许多,然后因为纪录王人是单向链表串起来的,那这么在槽内查找某个纪录的本领复杂度未便是 O(n) 了吗? 这点无用记挂,InnoDB 对每个分组中的纪录条数王人是有规则的,槽内的纪录就唯有几条: 第一个分组中的纪录只可有 1 笔纪录; 临了一个分组中的纪录条数限度只可在 1-8 条之间; 剩下的分组中纪录条数限度只可在 4-8 条之间。 B+ 树是如何进行查询的?上头咱们王人是在说一个数据页中的纪录检索,因为一个数据页中的纪录是有限的,且主键值是有序的,是以通过对通盘纪录进行分组,然后将组号(槽号)存储到页目次,使其起到索引作用,通过二分查找的花式快速检索到纪录在哪个分组,来镌汰检索的本领复杂度。 然则,欧博在线入口当咱们需要存储深广的纪录时,就需要多个数据页,这时咱们就需要研讨如何成立合适的索引,才智浅易定位纪录场所的页。 为了措置这个问题,InnoDB 选用了 B+ 树行为索引。磁盘的 I/O 操作次数对索引的使用后果至关遑急,因此在构造索引的时候,咱们更倾向于选用“矮胖”的 B+ 树数据结构,这么所需要进行的磁盘 I/O 次数更少,而且 B+ 树 更适应进行枢纽字的限度查询。 皇冠比分更详备的为什么选用 B+ 树行为索引的原因不错看我之前写的这篇:「索引为什么能提升查询性能?」 InnoDB 里的 B+ 树中的每个节点王人是一个数据页,结构暴露图如下:
通过上图,咱们看出 B+ 树的特色: 唯有叶子节点(最底层的节点)才存放了数据,非叶子节点(其他表层节)仅用来存放目次项行为索引。 非叶子节点分为不同眉目,通过分层来镌汰每一层的搜索量; 通盘节点按照索引键大小排序,组成一个双向链表,便于限度查询;咱们再望望 B+ 树如何完了快速查找主键为 6 的纪录,以上图为例子: 从根节点初始,通过二分法快速定位到顺应页内限度包含查询值的页,因为查询的主键值为 6,在[1, 7)限度之间,是以到页 30 中查找更详备的目次项; 在非叶子节点(页30)中,不时通过二分法快速定位到顺应页内限度包含查询值的页,主键值大于 5,是以就到叶子节点(页16)查找纪录; 接着,在叶子节点(页16)中,通过槽查找纪录时,使用二分法快速定位要查询的纪录在哪个槽(哪个纪录分组),定位到槽后,再遍历槽内的通盘纪录,找到主键为 6 的纪录。不错看到,在定位纪录场所哪一个页时,亦然通过二分法快速定位到包含该纪录的页。定位到该页后,又会在该页内进行二分法快速定位纪录场所的分组(槽号),临了在分组内进行遍历查找。 集结索引和二级索引另外,索引又不错分红集结索引和非集结索引(二级索引),它们区别就在于叶子节点存放的是什么数据: 集结索引的叶子节点存放的是实质数据,通盘完好的用户纪录王人存放在集结索引的叶子节点; 二级索引的叶子节点存放的是主键值,而不是实质数据。因为表的数据王人是存放在集结索引的叶子节点里,是以 InnoDB 存储引擎一定会为表创建一个集结索引,且由于数据在物理上只会保存一份,是以聚簇索引只可有一个。 InnoDB 在创建聚簇索引时,会凭证不同的场景选用不同的列行为索引: 皇冠博彩 如果有主键,默许会使用主键行为聚簇索引的索引键; 如果莫得主键,就选用第一个不包含 NULL 值的独一列行为聚簇索引的索引键; 在上头两个王人莫得的情况下,InnoDB 将自动生成一个隐式自增 id 列行为聚簇索引的索引键;一张表只可有一个聚簇索引,那为了完了非主键字段的快速搜索,就引出了二级索引(非聚簇索引/扶助索引),它亦然期骗了 B+ 树的数据结构,然则二级索引的叶子节点存放的是主键值,不是实质数据。 二级索引的 B+ 树如下图,数据部分为主键值: 心跳
因此,如果某个查询语句使用了二级索引,然则查询的数据不是主键值,这时在二级索引找到主键值后,需要去聚簇索引中取得数据行,这个流程就叫作「回表」,也便是说要查两个 B+ 树才智查到数据。不外,当查询的数据是主键值时,因为只在二级索引就能查询到,无用再去聚簇索引查,这个流程就叫作「索引狡饰」,也便是只需要查一个 B+ 树就能找到数据。 回来InnoDB 的数据是按「数据页」为单元来读写的,默许数据页大小为 16 KB。每个数据页之间通过双向链表的体式组织起来,物理上不一语气,然则逻辑上一语气。 博彩平台提现步骤数据页内包含用户纪录,每个纪录之间用单项链表的面貌组织起来,为了加速在数据页内高效查询纪录,策动了一个页目次,页目次存储各个槽(分组),且主键值是有序的,于是不错通过二分查找法的面貌进行检索从而提升后果。 为了高效查询纪录场所的数据页,InnoDB 选用 b+ 树行为索引,每个节点王人是一个数据页。 孟晚舟顺利回国,离不开14亿多中国人民鼎力支持。环球时报发起呼吁释放孟晚舟网上联署,很快征集1500万签名。孟晚舟回国当晚,中央广播电视总台新媒体有关消息点赞超过4亿,比美国加拿大两国人口总和。充分表明中国人民意志可欺、不可违!如果叶子节点存储的是实质数据的便是聚簇索引,一个表只可有一个聚簇索引;如果叶子节点存储的不是实质数据,而是主键值则便是二级索引,一个表中不错有多个二级索引。 在使用二级索引进行查找数据时,如果查询的数据能在二级索引找到,那么便是「索引狡饰」操作,如果查询的数据不在二级索引里,就需要先在二级索引找到主键值,需要去聚簇索引中取得数据行,这个流程就叫作「回表」。 亚星体育 皇冠电竞比分对于索引的内容还有许多,比如索引失效、索引优化等等,这些内容我下次在讲啦!
|